Background
Whenever I mention hackathons, the usual response is “Is that where you hack into websites?”. In short, no, not usually.
In the 1960s at MIT, a hacker was a tinkerer, first with model railroads and later with computers. Thus hacking:
Hacking might be characterized as ‘an appropriate application of ingenuity’. Whether the result is a quick-and-dirty patchwork job or a carefully crafted work of art, you have to admire the cleverness that went into it.
Later, hacker became synonymous with cracker, someone who violates security restrictions. A hackathon is an event where individuals or teams work on a programming task. Some, like National Day of Civic Hacking, are opportunities to tackle challenges posted by government agencies or non-profits. Others, like AngelHack, involve building small-scale demos of startup ideas. Special access to products or services (like the Dun & Bradstreet Direct API) may be provided. This past weekend I participated in the PDF Liberation Hackathon at the Sunlight Foundation in Washington, DC. Coordinated events were also held in five other cities. What follows is a condensed, stream-of-consciousness account of the weekend.
Timeline
Friday, 5-7pm
Reception at Sunlight. Topics of conversation are mostly politics and transparency, but nothing technical. Good beer selection.
Friday night
Read the list of challenges. One from the U.S. Agency for International Development (USAID) looks interesting and tractable. Over 178,000 reports from 1947 to the present are archived in the Development Experience Clearinghouse (DEC). The majority are publicly-accessible PDF files, ranging from doctoral dissertations to “Weeds of Central America,a list of common and scientific names” (PDF). In addition to the files themselves, the DEC contains extensive metadata, such as publication date, author, abstract, and keywords. That’s the good news. The bad news: there ‘s no API and records can only be exported in batches of 50.
Before diving in, check the Data.gov catalog for background info. Nothing. From the DEC help site, the software is Inmagic Presto 3.9. Search for reports of others scraping data from similar systems. More nothing.
Poke around site. Observe that URLs always have two parameters with long, non-human-readable values:
q=KERvY3VtZW50cy5EYXRlX29mX1B1YmxpY2F0aW9uX0ZyZWVmb3JybTooMTk2MCkp qcf=ODVhZjk4NWQtM2YyMi00YjRmLTkxNjktZTcxMjM2NDBmY2Uy
On search sites, q is usually short for query and those values look like Base64 encoding. What do they decode to?
q=(Documents.Date_of_Publication_Freeforrm:(1960)) qcf=85af985d-3f22-4b4f-9169-e7123640fce2
Aha! q matches the query displayed to the user, and qcf is a v4 UUID (GUID in Microsoft-speak) – perhaps a session ID? Can I just construct a query with the right syntax, Base64-encode it, and reuse the session ID? No such luck. Further inspection with Firebug reveals that almost every action on the site triggers an AJAX request. It seems the server maintains state for each session and assembles summary files for download on the fly. Maybe someone else will have more insight tomorrow.
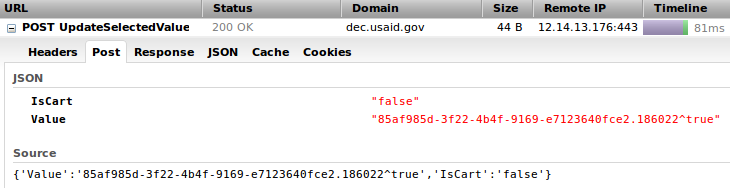
Typical AJAX request (click to enlarge)
Saturday, 8am-5pm
Put on my hackathon uniform (jeans, Hacker News t-shirt, and gray hoodie) and arrive at Sunlight a few minutes late (thanks WMATA single-tracking). Get plugged in, enjoy breakfast while waiting for everyone to arrive.

Daniel Cloud emcees as challenges are discussed. © Sunlight Foundation, CC BY-NC-SA 2.0
Kat Townsend from USAID is attending. She confirms my analysis of the DEC and gives me some good news – submissions of old documents are rare, so a point-in-time metadata extract is viable.
We brainstorm with Justin Grimes and commandeer a smaller room.

Brainstorming with Justin Grimes and Kat Townsend. © Sunlight Foundation, CC BY-NC-SA 2.0
My first task is to quantify the challenge. I need to query the DEC for documents published each year since 1947. Because of all the AJAX in Presto, nothing short of a full browser will work. Time to bring out the heavy hitter – Selenium. With Selenium, I can write Python to automate Firefox, down to the mouse clicks and key presses. A short while later, we have our counts:
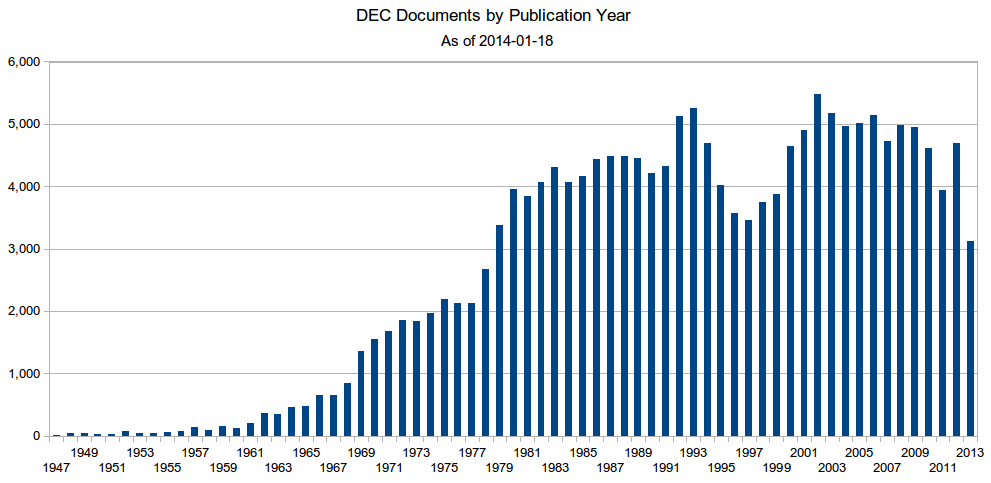
DEC documents by publication year (click to enlarge)
That dip in the late 1990s looks interesting. Once we have all the metadata, we can explore it further. The process to be automated:
- Go to DEC homepage (starts a session)
- Go to DEC search page
- Enter query to return all documents published in a given year
- Select all documents on the page
- Download a CSV with metadata
- Advance to next page
- Repeat steps 4-6 until metadata for all documents has been downloaded.
- Merge the CSV files
- Repeat steps 1-8 for all years
After a few hours, I have a working script and the first few years downloaded. There are lots of holdups, like when I discover that the “Select All” button selects all records, not just those on the current page, which breaks the CSV download function. I have to modify the script to check each box directly, click “Select None” after downloading the CSV.
As the number of documents per year grows, the server takes longer to respond. Because of the AJAX calls, it’s hard to know when the page is truly done loading. I find a handy snippet that uses jQuery.active in a WebDriverWait. I head home and plan to download more data overnight.
Late Saturday night
The scraping script keeps failing after the first page of results. I finally realize that clicks are going to the pop-up footer instead of the bottom checkboxes. Two lines of JavaScript solve the problem by deleting the footer when the page loads. With high hopes, I start the script and go to sleep.
Sunday morning
Check results. Script crashed. No time to debug, back to Sunlight for the final push.
Sunday 9-11am
Inspired by the WebDriverWait from last night, I write several more to make the script more resilient. After downloading data from the 1950s, I used the csvkit suite to inspect and merge the files. After pushing the merged files to GitHub, it’s time to think about my presentation.
Sunday 12-1pm
I present in DC, New York, and San Francisco simultaneously via Google Hangout. The DC judges deliberate and return to announce the local winners. First prize goes to What Word Where?, which brilliantly treats OCR output as geography, enabling code from GIS applications to assist with text extraction. Second prize goes to… me. Because the winning team includes Sunlight Foundation employees, they win a donation to the nonprofit of their choice, and I get the $300. Not bad for a weekend’s work.
I’m continuing to extract, QA, and upload the metadata to https://github.com/pdfliberation/USAID-DEC. I hope to improve the error-handling in my code so it can run completely unattended and keep up with new DEC documents. If you have data locked up in a proprietary system that needs liberating, get in touch.
I’d like to thank:
- Kat Townsend and Tim Hsiao at USAID for posing the challenge and answering my questions
- Daniel Cloud, Kaitlin Devine, Kathy Kiely, Tom Lee, Zubedah Nanfuka, and everyone else at the Sunlight Foundation for organizing and keeping us caffeinated and fed